|
||||
|
|
Невидимый ИнтернетФеномен невидимого Интернета и принципы работы с ним детально описаны в лучшей, на наш взгляд, книге по этому вопросу Криса Шермана и Гэри Прайса «Невидимый Интернет». Видимый Интернет – это та часть ресурсов, содержимое которой может быть обнаружено с помощью поисковых машин. К Невидимому Интернету относятся ресурсы, которые существуют в Глобальной Сети, и к которым можно получить доступ, если знать, где эти ресурсы находятся. Однако с помощью поисковых машин найти содержимое ресурсов Невидимого Интернета нельзя. По мнению разных авторов, к видимому Интернету относится порядка 20–30 % содержимого Сети. Самые смелые источники указывают другую цифру – не более 50 %. Таким образом, можно утверждать, что невидимый Интернет – это основная часть ресурсов, доступных онлайн. Причины существования невидимого ИнтернетаНевидимый Интернет существует в силу целого ряда причин, как технического, так и организационного характера. Некоторые ресурсы могут быть индексированы поисковыми машинами с технической точки зрения, главное – обнаружить содержимое страницы. Некоторые виды контента не индексируются информационными системами потому, что «пауки» сознательно настроены так, чтобы игнорировать те или иные адреса. К каким-то ресурсам доступ ограничили сами владельцы страниц. А некоторые страницы имеют такой формат, который пока еще не поддерживается поисковыми машинами. Вот что говорят о невидимом Интернете и причинах его существования Крис Шерман и Гэри Прайс.
Мы рассмотрим каждую из основных причин существования невидимого Интернета более подробно. Ограничения возможностей поисковых машин1. Физические ограничения скорости. Информационные системы имеют физические ограничения по скорости поиска новых страниц. Скажем так, скорость, с которой сегодня паук пытается найти новые страницы, оказывается ниже, чем скорость появления новых страниц. Ежесекундно идет негласное соревнование: в Интернете появляются новые страницы, а поисковые машины наращивают свою мощь. Кроме добавления новых страниц, в Интернете происходят еще и исчезновение старых, а также внесение изменений в содержимое существующих, что также оттягивает на себя часть ресурсов поисковых машин. В этой постоянной гонке Интернет выигрывает у поисковых машин с большим перевесом. 2. Поиск информации – мероприятие довольно дорогостоящее. Содержание сер веров, обеспечение подключений пользователей, рассылка пауков по Интернету, индексация, исключение сдвоенной информации – все это требует немалых затрат. Понимая, что проиндексировать все документы в Сети не реально, а расходы надо приводить в соответствие с доходами, владельцы поисковых машин вводят собственные ограничения в работе своих систем. Например, лимитируют глубину проникновения паука на сайте, общее количество страниц в индексе, пропускают старые ресурсы, на которые никто никогда не ходит, либо регламентируют частоту их повторных посещений пауком, в результате чего часть страниц устаревает. В любом случае, когда принимается решение о вводе ограничений на работу поисковой машины, это автоматически означает, что существуют страницы, которые могли бы быть проиндексированы, чего, однако, сделано не было. Такое положение вещей имеет необычный побочный эффект: большие сайты могут порой проигрывать небольшим по полноте охвата информационными системами. 3. Принцип попадания страниц в индекс при помощи пауков. Паук попадает только на те страницы, на которые есть ссылки с других страниц, либо по которым делались запросы в поисковые системы с целью уточнения рейтинга страницы в поисковой системе, либо которые внесены в очередь на индексирование вручную – путем заполнения формы «Добавить страницу» («Add URL»). Соответственно, если на страницу никто не ссылался, и никто о ней не сообщал поисковой системе вручную, то такая страница не будет проиндексирована. Кроме того, если даже паук регулярно посещает страницу, то он делает это с определенной периодичностью. Если в промежутке между двумя посещениями ресурс изменится, то это изменение некоторое время будет неизвестно поисковой системе и ее пользователям. Таким образом, существуют две задержки по времени в индексировании страниц: когда сайт создан, но еще неизвестен поисковику, и когда паук проиндексировал страницу, но не посетил ее повторно. 4. Необычные слова на странице, интересующей пользователя. Страница, которая нужна пользователю, может содержать слова, отличные от тех, которые он, вероятнее всего, введет в поисковую строку. В результате, человек, не обладающий большим опытом поиска информации в Интернете, не сможет найти нужную страницу с помощью поисковой машины. 5. Предпочтение поисковой машиной быстроты поиска, а не его глубины. Выбор между «максимально быстро» и «максимально полно» существует в любой отрасли, связанной с получением и обработкой информации. Поисковые системы обычно сориентированы их владельцами на наиболее быстрое получение результатов, пусть даже в ущерб полноте. Поэтому некоторые страницы, индексирование которых трудоемко, остаются за пределами базы данных, попадающей на сервер поисковой машины. Хотя бывают исключения из этого правила. Существуют специализированные поисковики, которые добывают информацию, копая вглубь и напрочь отметая критерий скорости ее нахождения. Но они при этом «ходят» лишь на тематические сайты. Примером такой специализированной системы может служить, по информации Гэри Прайса Law Crawler (http://lawcrawler.lp.findlaw.com/) или Politicalinformation.com (http://www.politicalinformation.com). 6. Ориентация поисковых машин на поиск текстов в разных вариантах. Поисковые машины изначально сориентированы на поиск текстов. На раннем этапе развития Интернета – представленных в формате HTML, после чего стали добавляться и другие их разновидности – Word (.doc), Adobe Acrobat (.pdf), Flash. Однако и эти форматы все равно содержат тексты. Индексировать изображения или, например, звуковые файлы (не названия звуковых файлов, а именно сам звук), поисковые машины пока не научились. Типы контента в невидимом ИнтернетеРазные типы контента по разным причинам могут стать частью невидимого Интернета. 1. Быстрое устаревание или изменение информации. Некоторые виды информации устаревают или меняются столь стремительно, что пауки просто не в состоянии ее проиндексировать своевременно. При этом часто владельцы поисковых систем вообще не пускают спайдеров на такие страницы, дабы не тратить ресурсы на бесполезное занятие. Примером такого контента может служить сайт о погоде в реальном масштабе времени. 2. Ресурсы состоят преимущественно из документов в таких форматах, которые не поддерживаются поисковыми машинами. Как, скажем, страница, содержание которой ограничивается одним лишь изображением. 3. Содержимое страницы генерируется по запросу и формируется пошагово. Примером в данном случае может служить ресурс, на котором осуществляется расчет цены автомобиля, в зависимости от комплектации и материала отделки салона. Для получения такой страницы пользователь пошагово заполняет формы на сайте, и конечный результат каждый раз формируется заново. Содержимое такой страницы не может быть проиндексировано по той простой причине, что без запроса страницы не существует, а заполнять формы паук не умеет. 4. Содержимое баз данных. Результат из базы данных также появляется лишь после ввода определенного запроса в форму обращения к ней. Паук, как и в предыдущем случае, не может ни заполнить форму запроса, ни проиндексировать содержимое самой базы. 5. Страница не вводилась в форму добавления сайта, не вводилась ни в какие формы проверки рейтинга на поисковых системах и при этом на нее не ведут никакие ссылки. Паук никоим образом не может узнать о существовании подобной страницы, а потому никогда ее не посетит. Эти страницы, кстати, могут представлять большой интерес для конкурентной разведки, поскольку на практике известны случаи, когда на них содержались эксклюзивные предложения для некоторых клиентов. Информация такого рода ориентирована на целевые группы и выкладывается на сайте, клиентам же присылаются ссылки на нужные страницы. Последние представляют бесценную находку для компаний, работающих на рынках с высокой конкуренцией, поскольку содержат ответ на вопрос о том, по каким ценам соперник реально продает свою продукцию. Мы сталкивались с ситуацией, когда компания смогла вычислить алгоритм составления адресов таких страниц конкурентом, после чего была долгое время в курсе всех его специальных предложений – до момента смены системного администратора конкурента. Примеры поведения поисковой машины при посещении страницы в ИнтернетеПридя на страницу, паук первым делом определяет, есть ли на сайте что-либо, что его владелец запрещает индексировать. Подобный запрет может быть реализован двумя способами. Первый заключается в том, что на сайте создается специальный файл robots.txt либо используется особый тег – так называемый, метатег <noindex>. В этот файл или под метатег «прячут» содержимое страницы, которое, по мнению владельца контента, не должно индексироваться поисковыми машинами. Единственное отличие между ними состоит в том, что <noindex> работает на той странице, на которой он расположен, тогда как robots.txt может быть использован с целью предотвращения индексации любых отдельных страниц, групп файлов или даже всего веб-сайта. По своей сути, никаких технических препятствий для индексирования содержимого ресурса этот способ не создает. Однако большинство поисковых машин с уважением относится к подобному способу защиты контента, который, как правило, не попадает в информационные системы. Наиболее близким аналогом столь действенного ограничения доступа в реальном мире можно считать таблички «м» и «ж» на дверях общественных уборных. На наш взгляд, метод ограничения индексирования с помощью файла robots. txt или метатега <noindex> потому получил столь большое распространение, что он препятствует работе пауков, но не мешает людям просматривать содержимое страниц без каких-либо ограничений. Второй способ охраны контента значительно надежнее первого и заключается в том, что страница защищается паролем. Паук технически неспособен вводить пароль. Однако и человек, прежде всего, должен этот пароль знать, а кроме того, ему необходимо потратить время и приложить усилия для того, чтобы его ввести. При такой защите ресурса работает уже не этический, а технический способ ограничения индексирования. После того, как паук попал на страницу, которая не защищена паролем и не внесена в список запрещенных, события развиваются по-разному, в зависимости от того, что на этой странице находится. Рассмотрим возможные их варианты, а также попытаемся понять, к видимому или к невидимому Интернету эти варианты относятся (по Крису Шерману и Гэри Прайсу). Вариант 1. Паук обнаруживает страницу, написанную в HTML и содержащую графические элементы. В таком случае паук может проиндексировать лишь название графического файла, и тогда такой документ будет найден при поиске картинок по ключевому слову, совпадающему с тем, которое есть в названии. Если имя файла не имеет ничего общего с его наполнением, он не сможет быть найден поисковой машиной, даже если будет содержать фотографию с изображением ключевого слова. Вариант 2. Паук внутри сайта столкнулся со страницей, которая написана на HTML, но содержит поля, требующие заполнения пользователем – например, ввода логина и пароля. В этом случае есть техническая возможность индексирования содержимого, но только того, к которому имеется доступ. Спрятанная под пароль часть страницы не может быть просмотрена и, как следствие, не может быть проиндексирована спайдером. Здесь наиболее часто встречаются два варианта. Первый: допустим, на сайте лежат готовые к просмотру страницы, на которые существуют ссылки в Интернете (например, фраза: «Я недавно интересную статью прочитал, она находится здесь:» – и далее следует прямой адрес статьи). В этом случае страница с формой, требующей заполнения, создана лишь для того, чтобы пользователь мог выбрать нужный ресурс из имеющихся. Текст на странице с формой будет виден пауку и проиндексируется, а сами страницы, на которые ведет форма, индексируются «в обход» процедуры ее заполнения, в другое время и, возможно, другим пауком, за счет ссылок на внутренние страницы сайта из других источников. В таком случае и страница с формой, и внутренние страницы будут относиться к видимому Интернету. Во втором варианте форма собирает информацию, на основании которой впоследствии создается необходимая пользователю страница. То есть, никакой внутренней страницы просто не существует до тех пор, пока форма не будет заполнена. Паук этого сделать не может. Данные, которые находятся внутри такого сайта, не могут быть получены никаким иным путем, кроме как посредством заполнения формы, а потому всегда относятся к невидимому Интернету. Вариант 3. Паук приходит на сайт, содержащий динамические данные, меняющиеся в реальном масштабе времени. К таким сайтам относится биржевая информация или, скажем, сведения о прибытии авиарейсов (рис. 2). Эти ресурсы обычно причисляют к невидимому Интернету, но не потому, что их технически нельзя проиндексировать, а потому, что их индексация не имеет практического смысла. 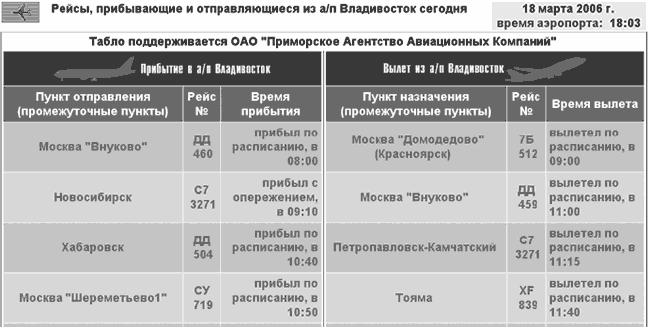 Рис. 2. Пример мониторинга движения рейсов на сайте www.airagency.ru Вариант 4. Паук попадает на страницу, которая содержит текст в формате, не поддерживаемом данной поисковой машиной. Например, Рамблер, как мы уже говорили, не поддерживает документы Power Point (.ppt). Ряд поисковых машин не индексируют документы в Postscript-файлах (это формат, в котором могут сохраняться для передачи в типографию файлы, созданные в программе Microsoft Publisher). До недавнего времени к таким форматам относился и PDF, однако сначала Гугл, а за ним и остальные поисковые машины стали индексировать подобные документы. Первоначально ограничение в работе с PDF-файлами было обусловлено тем, что на каждый новый формат приходилось расходовать дополнительные средства, распространенность же PDF-файлов вначале была невелика. Однако, по мере того, как правительственные организации многих стран стали выкладывать в Интернет документы именно в этом формате, поисковые машины начали с ним работать. Вариант 5. Паук находит базу данных, запрос в которую выполняется через веб-интерфейс. Причины, по которым такая база не может быть проиндексирована спайдером, следующие: – страницы генерируются динамически, в ответ на запрос; – протокол базы данных может не стыковаться с протоколом поисковой машины; – доступ к базе требует введения логина и пароля (особенно, если дело касается платных ресурсов). Четыре типа невидимости в ИнтернетеТрадиционно выделяют четыре типа невидимости содержимого Всемирной Паутины, сформулирванные Крисом Шерманом и Гэри Прайсом. 1. Невидимость, обусловленная настройками пауков и их естественными особенностями (так называемый, «серый Интернет»). «Серый Интернет» имеет несколько возможных вариантов. Ограничение глубины проникновения паука на сайт, настроенное владельцами поисковой машины. Изменения страниц, происходящие уже после посещения страницы пауком. Ограничение максимального количества показанных в выдаче страниц. Если, например, Яндекс в выдаче представил пять тысяч страниц, то посмотреть более одной тысячи не удастся – он их просто не покажет. Во всяком случае, так обстояло дело на момент написания книги. Исправить ситуацию можно за счет использования операторов запросов. В результате, количество страниц в выдаче уменьшится, с одновременным увеличением релевантности. 1.4.Страницы, не прописанные в форме «Добавить страницу» и не имеющие ссылок с других адресов. В мае 2000 г. IBM провела исследования, показавшие, что количество таких страниц, неизвестных поисковым системам, достигает 20 % от общего числа адресов, которые могли бы быть проиндексированы с технической точки зрения.[5] 2. Страницы, намеренно исключенные вебмастером из индексации. К ним как раз и относятся ресурсы, защищенные паролем или включенные в файл robots.txt либо убранные под тег <noindex>. 3. Страницы, которые требуют регистрации. В Интернете есть ресурсы, доступные бесплатно любому человеку, который для входа на страницу должен нажать кнопку «Я согласен»: это свидетельствует о его согласии с условиями посещения сайта. Иногда вместо такого выражения согласия требуется заполнить какие-то регистрационные формы. Паук не умеет выполнять подобные действия, и потому не попадает на сайт. 4. Действительно невидимый Интернет. Страница содержит данные в формате, недоступном поисковым машинам. Страницы намеренно не обслуживаются поисковыми машинами по тем или иным причинам. Информация хранится в базе данных и доступ к ней возможен лишь при условии заполнения определенной формы. Особенности построения адресов некоторых страниц ИнтернетаСоветуем разобраться в данном вопросе, поскольку это позволит лучше ориентироваться в Интернете, а также эффективно обходить проблемы, которые нередко возникают при попытке поставить некоторые страницы на мониторинг, с целью автоматического обнаружения изменений их содержания. Нередко ресурс может включать одновременно и элементы видимого, и невидимого Интернета. Иногда веб-мастера принимают меры к тому, чтобы заведомо исключить попадание своего сайта в разряд невидимых, с точки зрения некоторых поисковых машин, сохранив при этом ресурс удобным в использовании и внешне привлекательным для пользователей. Для этого в ряде случаев сайты, написанные, например, на Flash, имеют HTML-копии. Такие копии называют «зеркалами» страницы, они позволяют увидеть ее содержимое с помощью тех информационных систем, которые имеют какие-то затруднения в работе с форматом основного варианта сайта. Прямой и непрямой URL. Динамические страницы.Еще недавно в специальной литературе, изданной за рубежом, говорилось о том, что страницы, имеющие непрямой URL, как правило, относятся к невидимому Интернету. Сегодня ресурсы с непрямым адресом могут нормально индексироваться поисковыми машинами. Однако попытки специалистов конкурентной разведки поставить их на мониторинг могут натолкнуться на неожиданную проблему, которая, тем не менее, может быть преодолена. Если адрес страницы состоит только из букв, цифр и косых черточек, то это прямой url страницы, которая относится, как правило, к видимому Интернету. Примеры прямого URL: http://www.yandex.ru/; http://yushchuk.livejournal.com/35905.html. Сложнее обстоит дело со страницами, где в адресе встречается вопросительный знак, после которого следует множество непонятных неподготовленному человеку символов. Обычно все, что расположено левее вопросительного знака, приведет вас на страницу с формой, требующей заполнения или просто на одну из первых страниц сайта, а вот правее вопросительного знака часто записана информация, описывающая запрос. В качестве примера приведем адрес страницы, которая показывает результаты по запросу «маркетинг» в Яндексе: http://www.yandex.ru/yandsearch?text=%EC%E0%F0%EA%E5%F2%E8%ED%E3&stype=www. К этому адресу мы обратились для того, чтобы с его помощью разобраться в способах решения типичной проблемы. Поэтому чуть позже мы к нему вернемся. Непосредственно в этой правой части адреса страницы может содержаться описание критериев запроса – и тогда вы попадете на страницу еще раз, введя этот адрес в адресную строку браузера. А может запрос там и не содержаться, и тогда вам не удастся повторить переход на нужную страницу, введя адрес такой страницы в адресную строку браузера. В этом втором случае попытка перейти по адресу страницы приводит к загрузке незаполненного шаблона. Рассмотрим два примера, когда запросы одинаковы, но сайты устроены по-разному, что приводит к разным результатам. Итак, для наглядности поищем людей, которые разместили свои резюме в регионе «Екатеринбург» на сайтах Superjob.ru и e1.ru, причем анкеты их должны содержать слово «повар». При этом, заполняя формы запроса, мы намеренно не будем указывать никаких ограничений по полу, возрасту, образованию и прочим параметрам, дабы это не привело к возникновению дополнительных переменных величин поиска. Вот адрес страницы, выдаваемой в ответ на запрос, на сайте Superjob.ru:
В приведенной выше строке адреса описаны город (он имеет номер 33 по классификатору сайта и отражен в символах «town=33», а также слово «повар», на кодировке которого мы пока не будем останавливаться подробно). Если скопировать этот адрес в поисковую строку браузера, то можно вновь получить страницу с информацией о людях с требуемыми параметрами, как если бы мы ввели ее с клавиатуры заново. Вид страницы по этому запросу приведен на рис. 3. 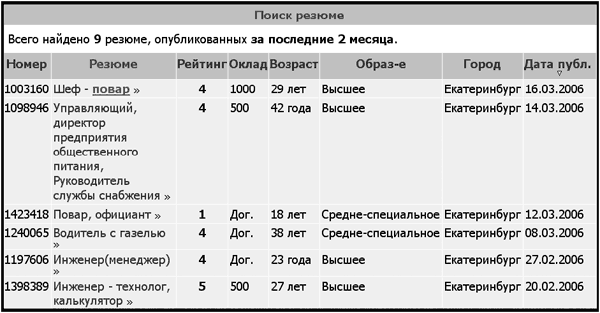 Рис. 3. Результат запроса на сайт Superjob.ru в поисках повара в Екатеринбурге. Вот ответ на такой же запрос с сайта e1.ru при тех же критериях поиска был получен результат, отображенный на рис. 4. 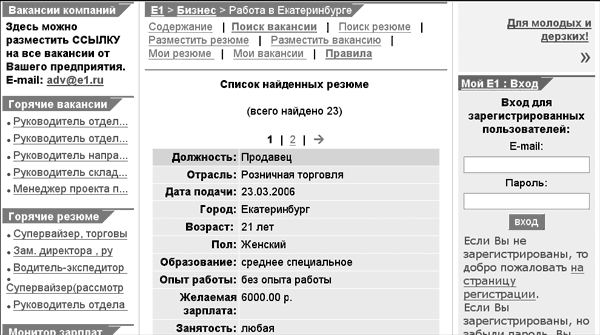 Рис. 4. Результат запроса на сайт e1.ru в поисках повара в Екатеринбурге. Адрес страницы, показанной на рис. 4, выглядит следующим образом: http:// www.e1.ru/business/job/resume.search.php. Не нужно быть в высшей степени сведущим относительно всех премудростей Интернета, чтобы заметить: адрес этот выглядит гораздо короче предыдущего. Кроме того, в нем отсутствует описание запроса. Попытка перейти повторно на нужную страницу, просто введя в поисковую строку браузера вышеуказанные координаты, как раз и приводит к незаполненной форме. Связано такое положение вещей с тем, что в принципе существует два типа запросов – так называемые GET и POST. При запросе типа GET параметры поиска указаны в адресной строке, поэтому переход по такому адресу приводит на нужную страницу (этот запрос выглядит как достаточно длинная строка с множеством символов, в том числе знаком «%» или с большим количеством англоязычных слов). Метод POST не подразумевает передачу параметров поиска через адресную строку. Данные о запросе передаются отдельно, по служебным каналам и не могут быть просмотрены обычным пользователем. Тем не менее, часто и в такой ситуации можно найти решение. Если на странице, которая изображена на рис. 8, перейти по ссылке на вторую страницу результатов запроса (кликнув мышкой по цифре «2» в перечне страниц), то адрес этой второй страницы будет содержать параметры поиска: http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EF%EE%E2%E0%F0+%EE%F4%E8%F6%E8%E0%ED%F2&search_by=1&show_for=7&order_by=2&search=yes&page=1. Видно, что адрес стал длинным, и в нем появилось множество символов, которых не было вначале. Интересно, что если после этого кликнуть по ссылке первой страницы и именно таким путем вернуться на первую страницу, то у нее также появится адрес, содержащий описание самого запроса и позволяющий при вводе его в адресную строку браузера попадать непосредственно на эту первую страницу: http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EF%EE%E2%E0%F0+%EE%F4%E8%F6%E8%E0%ED%F2&search_by=1&show_for=7&order_by=2&search=yes&page=0. Мы приводим эти, на первый взгляд, абстрактные для гуманитариев закорючки не из любви к теории. Практическое значение подобного явления становится понятно, когда возникает необходимость поставить на мониторинг страницы сайта, имеющего подобные алгоритмы работы. Ведь этот «длинный» адрес первой страницы, полученный путем перехода на вторую страницу и возврата с нее обратно на первую, можно поставить на мониторинг. Казалось бы, проблема решена. Но и тут не исключены сложности. Хорошо, когда можно перейти с первой страницы на вторую, а затем вернуться. Однако по некоторым запросам страница бывает всего одна, поэтому перейти с нее просто некуда. Выход и в таком случае есть. Правда, он несколько сложнее тех решений, о которых речь шла выше. Предлагаем рассмотреть данный вопрос более подробно, поскольку соответствующей литературой, как нам кажется, он пока еще специально не освещался. А кроме того, научиться ставить подобные сложные страницы на мониторинг отнюдь не помешает – это очень экономит время. Предлагаемое решение разработано нами совместно с участниками форума на сайте e1.ru в Екатеринбурге и со слушателями нашего курса «Маркетинг рисков и возможностей: конкурентная разведка». Итак, постараемся максимально доступно изложить весь алгоритм действий, чтобы он был понятен как можно более широкому кругу пользователей. Для того чтобы решить проблему постановки на автоматический мониторинг страниц, которые выдаются в ответ на запрос в единственном экземпляре, следует обратиться к базе данных таким образом, чтобы можно было заведомо рассчитывать на результат, состоящий из более чем одного ресурса. Применительно к сайтам вакансий и резюме это должны быть массовые специальности. Зададим поиск по признаку (по ключевому слову) «Менеджер» на странице поиска резюме на сайте e1.ru (рис. 5).  Рис 5. Введен запрос по слову «Менеджер» в форме поиска резюме не сайте e1.tif. Получив результат – первую страницу, мы точно так же, как в предыдущем случае, перейдем на вторую, кликнув по ссылке с номером страницы «2». Ее адрес (URL) выглядит так: http://www.e1.ru/business/job/resume.search.php?sex=l&key_words=%EC%E5%ED%E5%E4%E6%E5%F0&search_by=1&show_for=7&order_by=2&search=yes&page=1. Затем вновь вернемся на первую страницу, точно так же кликнув по ссылке страницы «1». После этого, как мы говорили ранее, в браузер будет загружена первая страница, полученная возвратом со второй. Ее URL выглядит следующим образом (это реальный адрес): http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EC%E5%ED%E5%E4%E6%E5%F0&search_by=1&show_for=7&order_by=2&search=yes&page=0. Сравните адреса первой и второй страниц. Видно, что они почти идентичны, за исключением последнего знака: вторая страница в конце адреса содержит цифру «1», а первая – цифру «0». Кстати, заметим, что третья страница будет оканчиваться на «2» – это подтверждено экспериментально. Теперь обратите, пожалуйста, внимание на сам набор символов: «%EC%E5%ED%E5%E4%E6%E5%F0». Он начинается после знака «=» и заканчивается перед знаком «&». Этот перечень и представляет собой слово «Менеджер», написанное в определенной кодировке. В данном случае нам неважно, как она называется, гораздо существеннее то, что это стандартная кодировка, которая применяется во всех системах. Если же кому-то из читателей это все-таки интересно, то сообщаем, что именуется она не иначе как UrlEncode, а то, что стоит после знака процента, – код символа в UTF-8. Научившись разбираться во всех приведенных нюансах, вы сможете автоматизировать процесс создания набора символов для подобных сложных страниц. Причем изучать кодировки для этого совершенно не требуется. Проведем простейший эксперимент: наберем в поисковой строке Яндекса слово «Manager», а в отдельном запросе – слово «Менеджер» и сравним URL’ы страниц, которые будут получены в ответ. Итак, адрес страницы по англоязычному запросу «Manager» выглядит следующим образом:
А вот так выглядит URL ресурса по русскоязычному запросу «Менеджер»:
Очевидно, что кодированные тексты в запросе резюме на сайте e1 и на Яндексе по слову «менеджер» идентичны и имеют вид
Мы уже располагаем примером синтаксиса строки страницы номер один с сайта e1 по запросу «менеджер»: Можно произвольно подставлять любое нужное слово, предварительно получая его закодированное написание в Яндексе, и таким образом принудительно генерировать на сайте e1 и ему подобных ресурсах нужные страницы с нужным форматом адреса, который впоследствии технически можно ставить на автоматический мониторинг. Проверим это утверждение на примере запроса по ключевому слову «Автоленд». Написание слова «Автоленд» в URL’е, полученное с помощью запроса в Яндексе, выглядит так:
Если механически подставить это значение в строку запроса по поиску вакансий на сайте e1 для первой страницы выдачи, то адрес будет выглядеть следующим образом: Подставив эти координаты в адресную строку браузера, мы получили всего одну страницу, на которой содержалось резюме конкретного специалиста. В тексте этого документа была информация о том, что человек действительно работал когда-то в компании «Автоленд». Однако помимо всего описанного выше, долгое время существовала еще проблема индексации динамически генерируемых страниц, которая относила их к невидимому Интернету. Динамические страницы – это ресурсы, создаваемые небольшой программой – скриптом – в момент запроса браузера к серверу. Такая страница часто имеет вид:
где aaaa – название скрипта, а после «?» идут параметры, включенные в запрос. Обычно динамические страницы определяются пауком на том основании, что они содержат символы
Большинство поисковых систем до недавнего времени старались обходить такие страницы стороной, т. к. паук вполне мог на них «зависнуть» навсегда, в силу технических причин – потому что он непрерывно пытался посетить несуществующие страницы, адреса которых практически до бесконечности может генерировать скрипт. Динамические страницы очень удобны для производства сайтов, и игнорировать их было бы недальновидно. Поэтому в последнее время крупнейшие поисковые системы стали одна за другой объявлять о том, что они начинают индексировать такие ресурсы, так что сайтов, которые относились прежде к невидимому Интернету в силу того, что содержали динамические страницы, стало меньше. Преимущества невидимого ИнтернетаПоисковые системы удобны, поскольку позволяют проводить поиск по ключевым словам. Однако все популярные поисковики такого плана – вроде Яндекса, Гугла и Рамблера, – рассчитаны на широкую, а не целевую аудиторию. В то время как невидимый Интернет изобилует источниками, посвященными определенной теме: они подобраны и проверены специалистами вручную и потому в большинстве случаев содержат наиболее полную и подробную информацию по конкретному вопросу. Так, на сайте проекта «Рифпарк», расположенном по адресу http://rifpark.ru/, вы можете ознакомиться с материалами по аквариумистике, многие из которых взяты из видимого Интернета и собраны вместе на данном ресурсе, оценены специалистами на предмет компетентного подхода к проблеме и представлены в виде тематических каталогов. При этом часть материалов из каталога сайта «Рифпарк» на момент написания книги была не проиндексирована поисковыми машинами, несмотря на то, что главная страница ресурса проиндексирована была. Например, фраза: «Водоросли обычно придают аквариуму неэстетичный вид (хотя в природе они встречаются повсеместно) или служат индикатором плохого качества воды», – взятая с этого сайта, при поиске по ней информации в Яндексе не вывела нас на ссылку, которая указывала бы на ресурс проекта «Рифпарк». Были найдены другие сайты с таким же текстом. Это видно на рис. 6.  Рис. 6. Яндекс не видит сайта «Рифпарк» при запросе фразы с этого сайта. Как указывают эксперты по поиску в Интернете, поисковые машины общего назначения постоянно выбирают между тем, какой ответ предоставить: самый простой, самый полный, самый интересный… (перечень критериев можно продолжить – вплоть до «наилучшего»). Как мы уже говорили, эти системы вынуждены ограничивать себя в процессе удовлетворения запроса пользователя, так как их работа имеет определенную себестоимость. Поисковик – коммерческое предприятие, ничего уж тут не поделаешь. С другой стороны, правительства, учебные заведения и другие организации, не преследующие целей получения прибыли, очень активно используют ресурсы невидимого Интернета. Такие сайты не стараются угадать интересы каждого, «заточены» под потребности представителей определенной отрасли и очень часто дают полный ответ на вопрос, на котором, собственно, и специализируются. Ответ этот, как правило, позволяет провести исчерпывающий поиск в конкретной предметной области и оперативно обновлять результаты. Таким образом, нередко невидимый Интернет имеет преимущества перед видимым: – фокусируется на узкоспециальном контенте, что позволяет ему обеспечивать более полные результаты; – часто имеет соответствующий своей теме поисковый интерфейс, отчего запросы могут настраиваться более точно, нежели в поисковой машине общего назначения, а значит, и ответы получаются более релевантными; – экономит время, а кроме того – может содержать информацию, которая нигде более недоступна. Это происходит, в частности, оттого, что в каталог невидимого Интернета его энтузиасты нередко включают информацию, взятую из базы данных, которая не индексируется поисковыми машинами, либо помещают фотографию документа, сделанную такими пользователями лично. Кроме того, если на каком-то форуме появляются интересные сведения, то они в ряде случаев просто стираются модератором или самим автором. Но до того как информацию успеют убрать, она зафиксируется одним из энтузиастов и будет храниться затем на его тематическом сайте. Когда использовать невидимый ИнтернетИтак, мы можем констатировать, что при поиске узкоспециальной информации после просмотра того, что будет предложено поисковиками, следует непременно обратиться к специализированным ресурсам. Особенно когда задача заключается не в одном лишь нахождении ответа на вопрос вроде: «В каком году был открыт Кутаисский автомобильный завод?» (это, кстати, реальный вопрос с Форума Яндекса[6]), – а подразумевает сбор максимально полной информации по той или иной проблеме. Как уже было сказано, часть сведений на таких сайтах может относиться к видимому Интернету, а часть – к невидимому. Есть смысл попытаться не ограничиваться поисковыми машинами, а отправиться на тематические сайты и поискать там информацию, которая может относиться к Невидимому Интернету, в следующих ситуациях. 1. Когда вы хорошо ориентируетесь в предмете. Специалисты в своем деле обычно знают один или более ресурсов, которые располагают необходимой им информацией. Часть таких адресов относится к невидимому Интернету. Компетентность человека в изучаемом предмете обеспечивает еще одно преимущество: настоящий профессионал быстро приходит к пониманию того, какие ключевые слова дают наилучший результат при поиске нужных сведений и в других базах данных. 2. Когда вы хорошо знакомы со специфическим поисковым инструментом. Некоторые ресурсы невидимого Интернета охватывают различные области знаний, но имеют при этом столь развитый и тонко настроенный поисковый инструмент, что, умея им пользоваться, можно достичь результатов лучших, нежели те, которые будут представлены поисковыми машинами общего назначения. Возможность точного составления запроса позволяет лучше искать иголку в стоге сена. Это справедливо и для ряда ресурсов видимого Интернета. Чтобы убедиться в этом, достаточно сравнить ответ на запрос с множеством параметров, который можно ввести, например, при поиске нужного резюме на сайте, посвященном поиску работы, и ответы на такой же запрос к поисковой машине, например, к Яндексу. 3. Когда вам требуется исчерпывающий результат, который заведомо проверен людьми, ориентирующимися в изучаемой области. Поисковые машины неспособны сравниться по этим параметрам с ресурсами невидимого Интернета. Глубина индексирования, несвоевременность, фильтрация результатов приводят к тому, что появляется много «шума». Проблему усугубляет отсутствие у большинства поисковых систем инструментов тонкой настройки запроса. Именно этот критерий – один из основных, на наш взгляд, по которому Гугл, имеющий одно логическое «И», проигрывает Яндексу, располагающему аж тремя логическими «И». 4. Когда стоит задача получить лишь своевременный контент. Страницы невидимого Интернета и тематические ресурсы в ряде случаев обновляются чаще, чем страницы и директории, индексируемые поисковыми машинами. Это связано с тем, что добровольцы-энтузиасты с большим рвением отслеживают изменения на тематических сайтах, в отличие от беспристрастных и ничем не интересующихся пауков поисковых машин. Плюсы и минусы директорий как способа поиска информации в ИнтернетеНезависимо от того, к видимому или к невидимому Интернету относятся директории, у них есть ряд общих положительных и отрицательных свойств. 1. Директории всегда относительно невелики по размеру – в сравнении с общим количеством информации, доступной через поисковые машины. Поскольку директории отбираются вручную, они, по определению, содержат информации меньше, чем любая поисковая машина. Однако такое ограничение имеет как плюсы, так и минусы. К преимуществам директорий относится их прямая нацеленность на заданную проблему. Редактор, который принимает решение о включении каких-то данных в тематическую директорию, должен оценить соответствие этой информации теме, и поэтому для каталога отбираются лишь высококачественные ссылки. Кроме того, к каждой статье в директории прилагается аннотация, из которой сразу становится понятно, имеет ли смысл пользователю идти по конкретной ссылке в поисках определенной информации. К минусам, связанным с небольшими размерами директорий и ограниченной численностью персонала, который их обслуживает, относится неспособность редактора понять нюансы той или иной узкой проблемы и, как результат, исключение некоторых пограничных вопросов из перечня тем. Надо сказать, что некоторые каталоги пошли по пути организации онлайновой энциклопедии – Википедии, когда сами пользователи решают, что соответствует, а что не соответствует их теме. Такие базы данных получают преимущество перед традиционными, которые контролируются лимитированным штатом редакторов. Что интересно, первоначально существовали опасения, что подобные возможности правок приведут к появлению тотальной анархии. Как и в ситуации с Википедией, практика показала, что все эти домыслы оказались беспочвенными. 2. Редакторская политика бывает очень субъективной. Хотя редакторские стандарты и критерии отбора информации заявлены уже на входе в каждую директорию, другие факторы также могут влиять на качество ее содержимого. Так, у редактора могут быть «любимые» и «нелюбимые» темы. В открытых каталогах может быть собрано много информации, но такой специалист имеет возможность, например, убрать данные о конкуренте. Хорошая директория старается сохранить объективность и предоставить разные точки зрения, однако далеко не всегда это удается сделать на практике. 3. Несвоевременность. Мы уже говорили, что на специализированных сайтах, благодаря работе энтузиастов, достаточно оперативно отслеживаются изменения по тематическим вопросам. Однако это происходит не всегда. К сожалению, нередко адреса и содержимое страниц могут меняться со временем, но далеко не всегда это находит оперативное отражение в содержании директории. Теоретически за этим должен следить редактор, однако на практике все подчас складывается иначе, хотя бы в силу банальной нехватки времени. В связи с этим многие из них просят сообщать о так называемых «битых и удаленных ссылках», но те адреса, которые посещаются мало, могут быть пропущены и не отслежены с помощью этого фильтра. Кроме того, нередко картину в каталогах портит тактика неких «дорвеев». Она нацелена на то, чтобы заманить на свой сайт пользователя, который бродит по Интернету в поисках определенного контента, а затем перебросить его на другой сайт, ради принудительного посещения которого первый сайт, собственно, и создавался, а после чего «раскручивался». Недобросовестный администратор такого сайта может дождаться, когда его сайт, соответствующий теме каталога, окажется включен в тематический каталог, а затем ставит так называемый редирект (перенаправление) на сайт, например, порнографического содержания. Именно из-за этой технологии люди, которые ищут, например, программное обеспечение для мобильных телефонов, часто при переходе по ссылке оказываются на сайте электронного казино или на ресурсее, предлагающем интимные услуги. 4. Перекос информации в одну сторону. Директории могут не отражать реального баланса информации, содержащейся в Интернете, поскольку информация отфильтровывается заведомо предвзято. Для директорий, имеющих узкую направленность, это не является недостатком, скорее наоборот. А вот для директорий общего назначения это критично. Ситуацию усугубляет то обстоятельство, что некоторые «раскрученные» ресурсы берут плату за включение новых сайтов в свои каталоги, что может приводить к исчезновению действительно нужного контента и замене его на бесполезный, но проплаченный в рекламных целях. С другой стороны, как недостаток, так и избыток информации могут создавать проблемы, так как перенасыщение Сети материалами заметно усложняет процедуру поиска нужного ресурса. Примером перегруженных директорий, содержащих тысячи документов, может служить категория «Производство и поставки «в Яндексе, которая на момент написания книги включала 8748 ссылок. Отчасти указанная проблема решается за счет хорошего структурирования материала, однако это не избавляет пользователя от необходимости затрачивать на поиск немалые усилия. Основные категории невидимого ИнтернетаКрис Шерман и Гэри Прайс еще в 2004 г. выделили основные категории онлайновой информации, которая чаще всех остальных сведений относится к невидимому Интернету – в той или иной степени. Мы бы рекомендовали материалы, подобные приведенным ниже, искать не только и не столько через информационные системы, сколько через специализированные сайты. При этом сами такие узконаправленные ресурсы (их главные страницы, а не содержимое) можно успешно отыскать при помощи тех же информационных систем. Мы попытались проанализировать, насколько изменилась ситуация по сравнению с той, что была описана Шерманом и Прайсом, а также проверить, как обстоят дела с подобными типами ресурсов в русскоязычной части Интернета. 1. Информация о компаниях, обязательная для раскрытия. Во многих странах компании, акции которых публично продаются, обязаны предоставлять определенную информацию о себе на правительственные сайты или сайты общественных организаций. Такие ресурсы нередко позволяют организовать информирование по электронной почте об изменениях информации о какой-либо компании. В России к таким сайтам относится сайт проекта СКРИН: http://www.skrin.ru/issuers/. 2. Номера телефонов. К невидимому Интернету часто относят так называемые «Белые страницы» или «White Pages» (справочники, содержащие информацию о телефонах отдельных людей), например справочник, расположенный по адресу: http://interweb.spb. ru/phone/. 3. Составление карт для водителей. Конкретная карта, составляется по запросу. Примеры: http://www.wayinnet.com/r/service/m2.htm http://www.licard.ru/wwwintra/licard_ru_route.nsf/RoutePlanning?OpenForm &lang=RU. 4. Патенты. Поиск по базам данных патентов в России предоставляется, в частности, на сайте Роспатента: http://www.fips.ru/russite/. 5. Книги, которые больше не печатаются. Книги, которые больше не печатаются, но представляют интерес для читателей, есть всегда. И это не обязательно антиквариат. Нередко люди ищут такую литературу просто из желания сэкономить, особенно если речь идет об иностранной печатной продукции. Для удовлетворения такого спроса созданы специализированные сайты. Напрмер, американский ресурс http://www.alibris.com или российский http:// www.alib.ru/. 6. Библиотечные каталоги. http://www.benran.ru/Lib_kat.htm Каталоги библиотек России: каталоги Российской государственной библиотеки; – каталоги Российской национальной библиотеки (Санкт-Петербург); – каталоги ГПНТБ РФ (включая Российский Сводный Каталог по научно-технической литературе); – каталоги Государственной центральной научной медицинской библиотеки; – каталоги Центральной научной сельскохозяйственной библиотеки; – каталог библиотеки МГУ. Каталоги зарубежных библиотек: – Библиотека Конгресса США; – Британская библиотека. Списки Интернет-каталогов библиотек мира: – каталоги национальных библиотек мира (Российская национальная библиотека); – LibDex – The Library Index; Lib-Web-Cats. A directory of libraries throughout the world. 7. Толковые словари или словари иностранных слов известных авторов, размещенные на крупных поисковых ресурсах в качестве дополнительной услуги для пользователей. Действительно, попытки найти значение слова «каталог» в словаре В. Даля через Яндекс «Словари» увенчались успехом. Был получен текст из сдоваря Даля:
Попытка найти это же определение с использованием части текста (с помощью оператора «двойные кавычки») также дала положительный результат, но на других сайтах, не имеющих отношения к Яндексу (рис. 7). 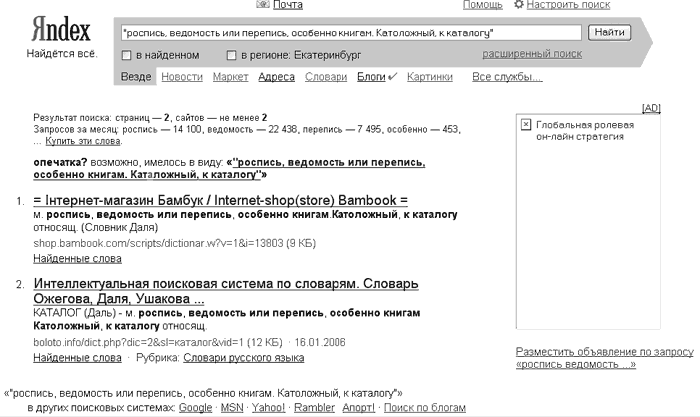 Рис. 7. Слово «Каталог» найдено на других сайтах при поиске через Яндекс. Попытка принудительно искать эту же часть текста именно на сайте Яндекса, с помощью оператора rhost, не дала результата. 8. История биржевых котировок. Многие люди считают, что биржевые данные – это недолговечная информация, которая быстро теряет свою ценность. Однако для аналитиков, составляющих тренды, эти сведения необходимы. В качестве примера приведем описанный Шерманом и Прайсом сайт BigCharts, представленный на рис. 8 и расположенный по адресу: http://www.bigcharts.com/historical/. 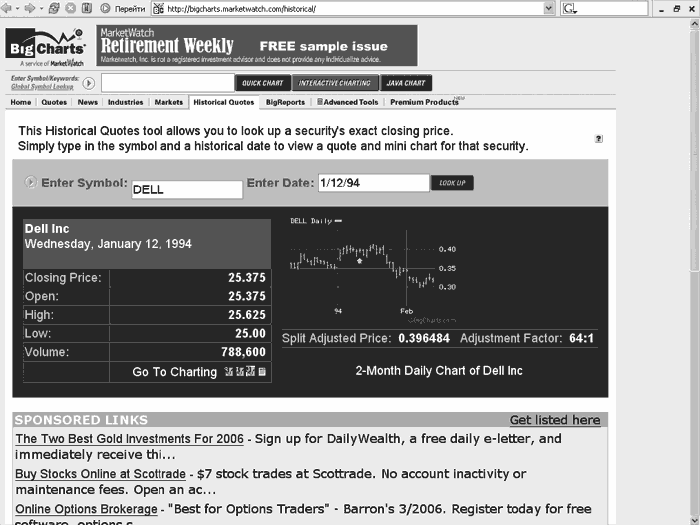 Рис. 8. История биржевых котировок на сайте BigCharts. Другим примером служит архив котировок Forex на ресурсе компании UMIS, находящемся по адресу: http://www.umis.ru/quotes_arch. 9. Исторические документы и рисунки. Многие исторические документы присутствуют в Интернете лишь как изображения, отсканированные с оригинала. Но рисунки плохо распознаются поисковыми машинами. Как, например, Манифест об основании Русского исторического Общества 23 мая 1866 г. в Санкт-Петербурге с сайта http://www.russkymir.ru/out.php?cat=2. 10. Директории отдельных компаний. Примером может служить сайт РАО ЕЭС http://www.rao-ees.ru/ru/ где есть ссылка на страницу «Сайты дочерних и зависимых обществ». 11. Экономическая информация. Правительства и государственные учреждения содержат целую армию статистиков, которые проводят мониторинг экономической ситуации. Этому вопросу посвящен сайт Росстата, на котором собраны данные по темам: http://www.gks.ru/wps/portal/. 12. Предложения вакансий и резюме о работе. Для поиска сотрудника или работы поисковые системы не особенно подходят: результаты, которые они при этом демонстрируют, не самые впечатляющие – как по релевантности, так и с точки зрения трудоемкости. В подобных случаях, к примеру, не лишне было бы обратиться к одной из многочисленных баз данных, которая находится на специальном ресурсе, посвященном поиску работы. Это могут быть http://www.superjob.ru/, http://megajob.ru/ или любой другой, подобный им региональнымй ресурс. Такие сайты обычно можно найти на сайтах городов или областей. Например, поиску работы или вакансий посвящен сайт Самары http://www.63. ru/job/index.php. 13. Инструменты по переводу. Онлайновые переводчики обеспечивают ценный сервис, когда переводят текст целых веб-страниц с языка, который вам незнаком. Такой переводчик, после ввода в специальное поле URL страницы, идет по указанному адресу, переводит весь текст на желаемый язык и показывает в браузере как динамически сгенерированный документ. Такой сервис предоставляется многими онлайновыми переводчиками, примером может служить переводчик «Babel Fish Translation» от поисковой машины AltaVista http://world.altavista.com/. 14. Данные о погоде. Существует множество сайтов, специализирующихся на информации о погоде, одна из таких служб интегрирована в Яндекс и расположена по адресу: http://weather.yandex.ru/. 15. Галереи искусств.  Рис. 9. Просмотр картин на сайте Эрмитажа. Многие галереи, начиная с крупнейших и заканчивая крошечными, все чаще и полнее оцифровывают свое собрание произведений и делают его доступным онлайн. Лучший способ увидеть экспонаты такого рода – это посетить ресурсы наподобие представительства Эрмитажа в Интернете (рис. 9), которое поддерживается при участии компании IBM: http://hermitage.museum.ru/. Интересный и перспективный, на наш взгляд, эксперимент проводит на сайте Эрмитажа IBM. Там представлена система поиска изображений по цветовым фрагментам, расположенным в определенном месте полотна: http://hermitage. museum.ru/fcgi-bin/db2www/qbicSearch.mac/qbic?selLang=Russian. Детальное описание этого инструмента приведено на сайте, и мы не будем на нем останавливаться, отметим лишь, что пользование этим поисковым инструментом IBM требует от человека изрядных художественных навыков. Чего вообще обычно не бывает в ИнтернетеИнтернет появился относительно недавно. Однако, несмотря на стремительное его развитие, далеко не все документы, созданные людьми, успели обрести оцифрованное обличие и попасть в Сеть. Каждый день эта ситуация улучшается, хотя, на наш взгляд, до решения проблемы еще далеко. Основные виды информации, которую в Интернете нельзя найти в принципе, представлены ниже, в соответствии с классификацией Шермана и Прайса. 1. Некоторые базы данных и информационные сервисы, которые доступны на платной основе и не выкладываются владельцами в Интернет. Ограничение доступа к этой категории сведений наиболее понятно. Закономерно, что базу данных Регистрационной палаты в Сети не найдешь. Она находится либо в самой Регистрационной палате, где и должна храниться, либо в том или ином виде продается на «черном рынке», чего, в принципе, быть не должно. 2. Многие государственные и общественные документы. Концепция цифрового правительства провозглашена, однако оно до сих пор не появилось. Многие документы, которые возникли задолго до изобретения Интернета, никто и не думал переводить в цифровой формат и, соответственно, публиковать в Интернете. Наиболее сложной остается ситуация с региональными приказами некоторых ведомств. Так, приказ Роспотребнадзора Свердловской области по одному из важнейших для любого бизнеса вопросов был на момент написания книги недоступен в Сети в принципе, а раздел сайта Роспотребнадзора, в котором он, по идее, должен был храниться в открытом доступе, находился «в стадии разработки». 3. Аналитическая информация, которая продается за деньги. Многие отчеты о маркетинговых исследованиях или полные тексты тренингов, проводимых известными специалистами, не попадают в Интернет потому, что авторы продают их непосредственно своим клиентам и сознательно препятствуют появлению этих материалов онлайн. 4. Полные тексты многих журналов и газет. Не все материалы переведены «в цифру». Часть материалов остается непереведенной из-за того, что просто до них не дошли руки. Другая часть, особенно за рубежом – потому, что не всегда удается урегулировать авторские права по старым материалам. Есть еще техническая проблема – некоторые материалы на бумажных носителях требуют усилий и материальных затрат по восстановлению текста, поскольку документы физически изношены и трудночитаемы. Кроме того, некоторые архивы просто не сохранились, в силу ряда причин – как, например, часть архива «Комсомольской правды», уничтоженная во время пожара. 5. Печатный материал не попадал в Интернет потому, что никто из людей, владеющих методами его перевода в цифровой формат и последующего размещения в Сети, пока что этими текстами не заинтересовался. Как говорится, руки не дошли. Ни у кого. И потребности не возникло оцифровывать тот или иной документ. Как следствие, найти его можно лишь в библиотеке, с помощью библиотечных каталогов. |
|
||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Вверх |
||||
|
|
||||